Chapitre 5 Analyse des données
Nous savons que les données écologiques et biologiques sont souvent complexes. De nombreux ensembles de données comprennent:
- Une structure hiérarchique des données
- Plusieurs covariables et facteurs de regroupement
- Une étude ou un plan expérimental non équilibré
Alors, comment pouvons-nous analyser nos données?
- Option 1: Séparer - Faire une analyse séparée pour chaque espèce et chaque lac.
- Option 2: Tout regrouper - Faire une seule analyse en ignorant les variables espèce et lac.
- Option 3: ?
Examinons de plus près ces options en utilisant notre ensemble de données sur les poissons!
5.1 Option 1: Nombreuses analyses séparées
Une façon d’analyser ces données est de faire des régressions linéaires pour chaque espèce dans chaque lac.
Voici à quoi cela ressemblerait pour l’espèce 1 dans le lac 1:
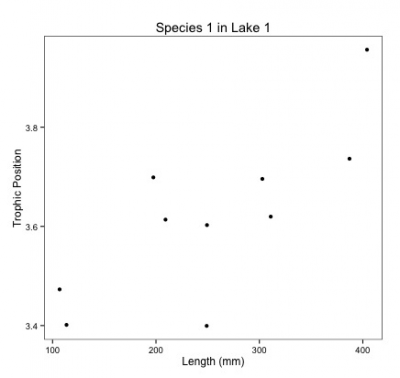
Remarquez que vous devez estimer une ordonnée à l’origine et une pente pour chaque régression (2 paramètres x 3 espèces X 6 lacs = 36 paramètres estimés) et la taille d’échantillon pour chaque analyse est de 10.
Il y a peu de chances de détecter un effet à cause de la faible taille d’échantillon et un taux d’erreur augmenté en raison de comparaisons multiples.
5.2 Option 2: Une analyse groupée
Une autre façon d’analyser ces données est de faire une seule analyse en ignorant les variables espèce et lac.
Voici à quoi cela ressemblerait pour toutes nos données dans tous les lacs à la fois:
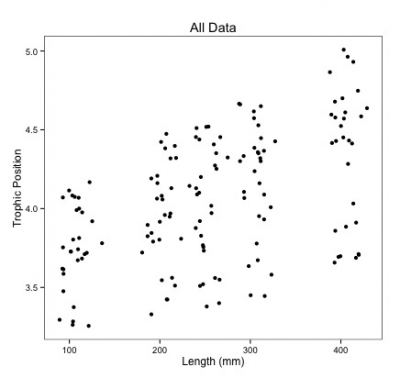
Remarquez que vous avez maintenant une taille d’échantillon énorme et beaucoup moins de paramètres à estimer!
Mais qu’en est-il de la pseudo-réplication? Les poissons d’un même lac et d’une même espèce peuvent être corrélés.
De plus, regardez tout ce bruit dans les données! Une partie pourrait être causée par des différences entre les espèces et les lacs.
5.3 Option 3: Est-ce qu’on a une autre option?
Pour notre question, on veut seulement savoir s’il y a un effet général de la longueur corporelle sur la position trophique.
Cependant, cette relation peut différer légèrement entre les espèces en raison de processus biologiques non mesurés (par exemple, le taux de croissance) ou entre les lacs en raison de variables environnementales non mesurées. Mais cette variation ne nous intéresse pas, nous devons donc trouver un moyen de contrôler ces effets potentiels tout en maximisant l’utilisation de nos données. C’est pourquoi la séparation et le regroupement seuls ne sont pas des options satisfaisantes.
Cela nous amène aux modèles mixtes! Les MLMs sont un compromis entre séparer et regrouper. Ils:
- prennent en compte la variabilité spécifique à chaque espèce et chaque lac (séparer) tout en calculant moins de paramètres qu’une régression classique;
- utilisent toutes les données disponibles (regrouper) tout en contrôlant les différences entre les lacs et les espèces (pseudo-réplication).
Ce faisant, ils:
- permettent d’utiliser toutes les données disponibles au lieu d’utiliser les moyennes d’un échantillon non indépendant;
- tiennent compte de la structure des données (par exemple, des quadrats imbriqués dans des sites imbriqués dans des forêts);
- permettent aux relations de varier en fonction de différents facteurs de regroupement (également appelés effets aléatoires);
- nécessitent moins d’estimations de paramètres que la régression classique, ce qui vous fait gagner des degrés de liberté.
Mais comment font-ils tout cela? Entrons dans le vif du sujet!