Chapter 7 How do LMMs work?
7.1 Parameters are varied
In linear mixed models, intercepts and/or slopes are allowed to vary according to a given factor (random effect; e.g. by lake and/or species).
Allowing intercepts and/or slopes to vary by random effects means that you assume they come from a normal distribution. A mean and standard deviation of that distribution are estimated based on your data. The most likely intercepts and slopes from that distribution are then fit by optimization (ex. maximum likelihood or restricted maximum likelihood).
Intercepts:
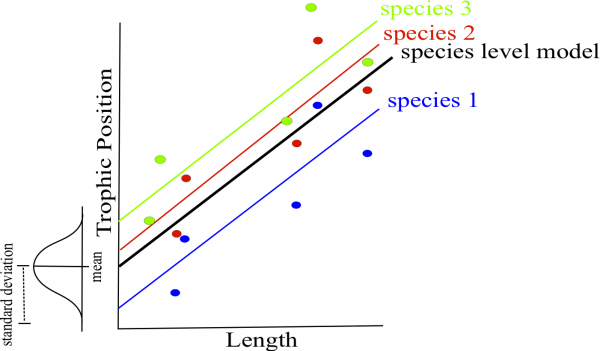
If we consider species as a random effect first, we can estimate a mean and standard deviation for the combined distribution of species intercepts rather than separate intercepts for each species. The mean of this distribution is the ‘species level model’.
In this example, we only have three species. In general, the more levels you have for a given factor, the more accurately the parameters of the distribution can be estimated (three may be a little low for estimating a mean and standard deviation but it makes simpler graphs!). Note that when you implement LMM’s in R, the intercept in the summary is the species level intercept (i.e. the mean of all random intercepts).
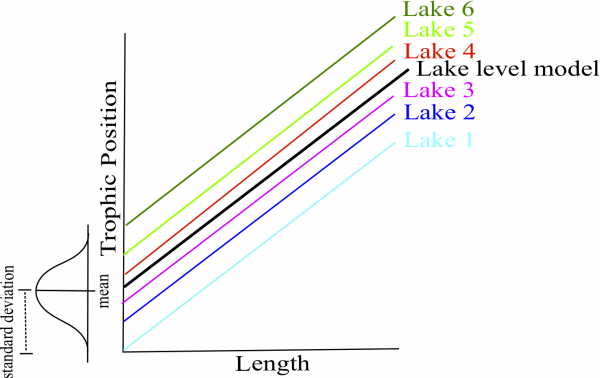
Likewise, if we consider lake as a random effect then only mean and standard deviation of the combined lake intercept are estimated. This saves you the need to estimate 6 different lake intercept parameters, ultimately saving degrees of freedom as less parameter estimates are needed given the amount of data.
Slopes:
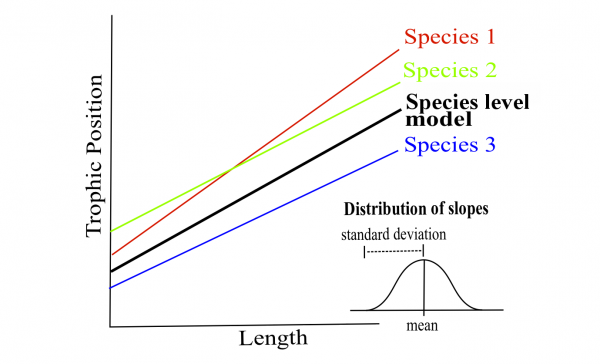
The same concept is used for allowing slope to vary by a given factor (random effect). This is a little harder to visualize than the intercepts.
In the case of species, the mean and standard deviation of slope parameters are estimated instead of three separate slopes. Note that when you implement LMM’s in R, the slope in the summary is the species level slope.
7.2 Data structure is taken into account
In linear mixed models, intercepts, slopes and their confidence intervals are adjusted to take the data structure into account.
What happens if the sample size for a specific factor level is small? (e.g. low \(n\) for a specific species)
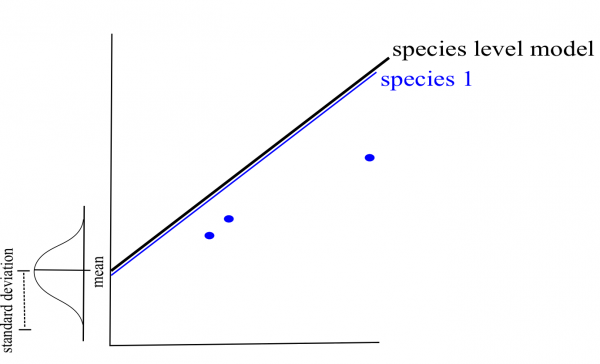
If a certain species or lake is poorly represented in the data, the model will give more weight to the pooled model to estimate the intercept and/or slope of that species or lake (i.e. shrinkage).
Ideally, you should have a minimum of \(n\) = 3 for any specific factor level.
How do we assess the impact of a random effect on the model?
The confidence intervals for the general intercepts and slopes are adjusted to account for pseudoreplication based on the intraclass correlation coefficient (ICC)
The ICC is calculated as the ratio of variance between the random effect and the total variance. Thus, the ICC describes the proportion of variance in the response variable that is attributed to a specific random effect:
\[ICC = \frac{\sigma_{\alpha}^2}{\sigma_{\alpha}^2 + \sigma_{\varepsilon}^2}\] Note: The specific mathematical notation may vary according to the article/book and according to how the model equation was written.
In our fish example, the ICC informs us of the extent to which the average trophic position (i.e. intercepts) varies among species or lakes.
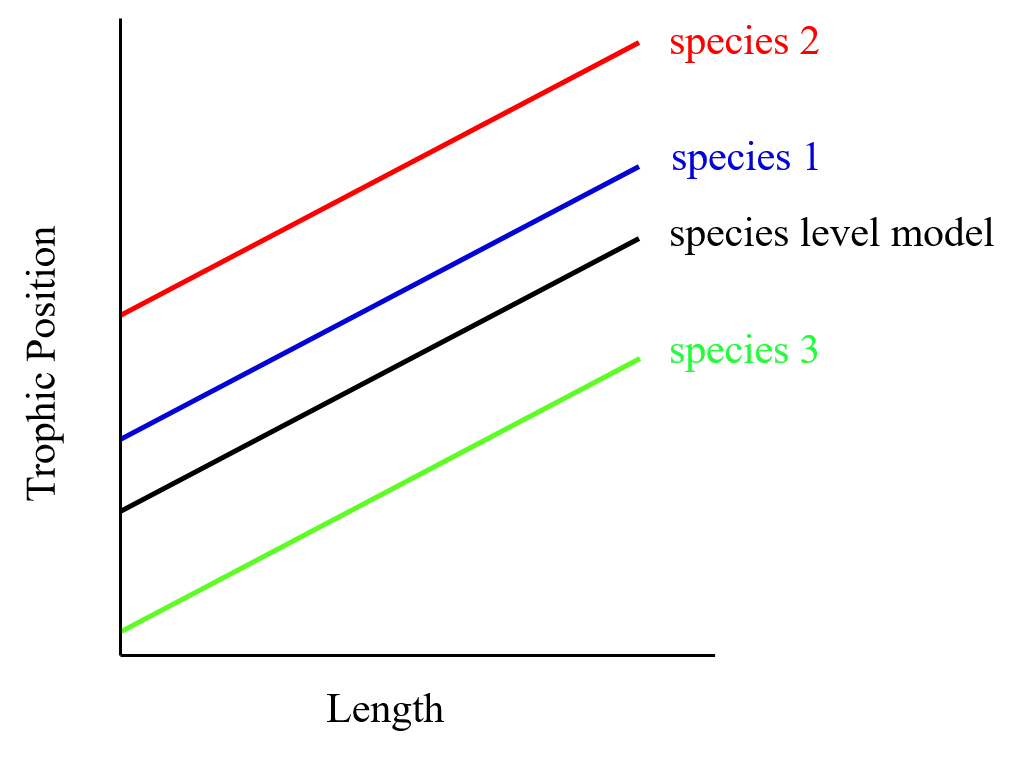
The % of variance (ICC) is high because species differ strongly in their average trophic position.
The confidence intervals for the general intercept and slope are high.
Low ICC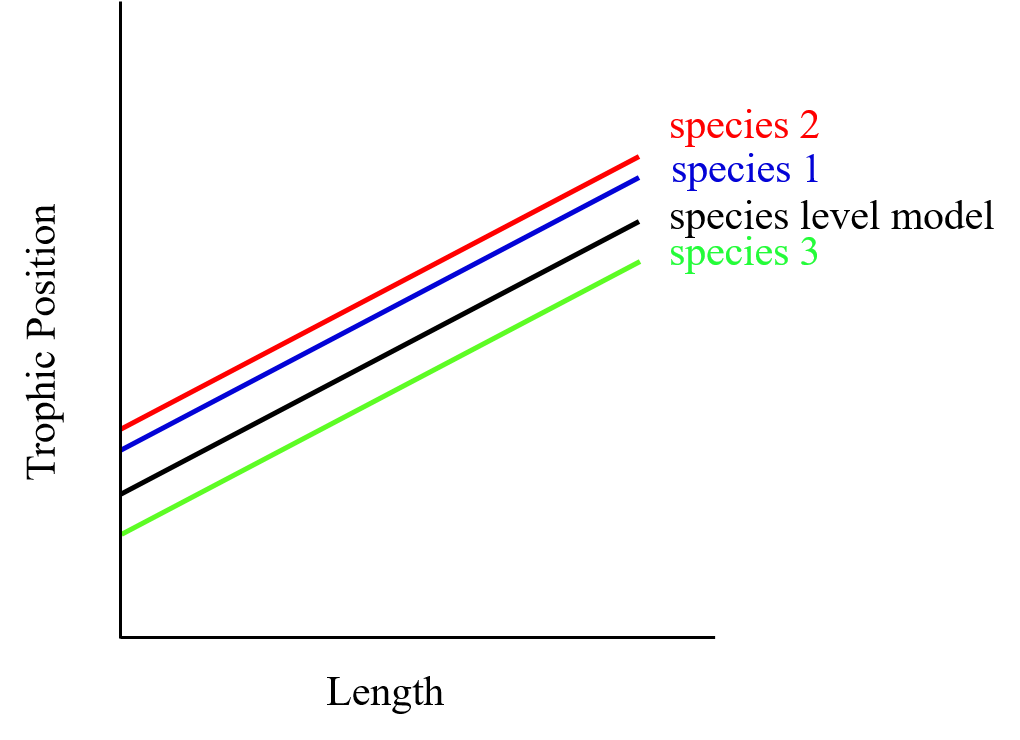
The % of variance (ICC) is low because species differ poorly in their average trophic position.
The confidence intervals for the general intercept and slope are small.
For more details on ICC: