Section 4 Développer
4.1 Directives
Ce guide est conçu pour aider les équipes de développement lors de la création et de la modification du contenu des ateliers R du CSBQ. Nous voulons nous assurer que les personnes qui assistent aux ateliers peuvent se concentrer sur le contenu présenté sans distraction par des questions de style, de grammaire, de ponctuation et/ou de structure.
Veuillez lire attentivement ce guide avant de commencer et vous y référer régulièrement pendant votre travail.
4.1.1 Principales priorités
Nous avons établi ici une liste de priorités pour les personnes qui souhaitent contribuer aux ateliers R. L’idéal serait que les équipes de développement accomplissent toutes ces tâches, mais si les circonstances rendent cela impossible, il est important de se concentrer sur les changements structurels avant les questions de style.
Une version de cette liste sous forme de liste de contrôle a été ouverte en tant que besoin dans le dépôt GitHub pour chaque atelier respectif. Nous vous suggérons d’utiliser ces listes de contrôle comme un moyen de suivre votre progression tout en travaillant et en vous coordonnant avec votre collègue développeur, le cas échéant. Elles peuvent également être utilisées comme référence pour rapporter le travail accompli aux coordinateurs de la série d’ateliers R du CSBQ, ou pour demander des heures supplémentaires.
Priorités générales:
Traiter les problèmes existants soumis à GitHub, qui sont notés dans la section “Issues” du dépot GitHub.
S’assurer que le code fonctionne correctement et que le code correspond à la présentation de l’atelier. Continuez à vérifier cela au fur et à mesure que vous apportez des modifications.
S’assurer que les versions francophone et anglophone d’un atelier sont toutes les deux mises à jour et que le contenu est équivalent.
Les ateliers ne doivent pas contenir des fautes d’orthographe, de grammaire ou de ponctuation.
Veiller à ce que les diapositives des ateliers soient rédigées dans un style cohérent, ce qui facilite le déroulement des ateliers et la compréhension. Cela est particulièrement important lorsque l’on travaille en collaboration dans une équipe de développement.
Dans la mesure du possible, ajoutez des notes de présentation aux diapositives que vous modifiez. Vous pouvez écrire des notes que vous pourrez lire vous-même en mode présentation quand vous appuyez sur le raccourci clavier
P. Ces notes sont écrites sous trois points d’interrogation???, avant la fin d’une diapositive. Voir l’exemple ci-dessous :
---
Le contenu de cet atelier est essentiel.
???
Note : _Chantez cette diapositive_.
---4.1.2 Règles structurelles
Ne laissez pas le contenu des diapositives déborder de l’écran.
Le code utilisé pour générer un résultat (chiffre ou calcul) doit correspondre au code affiché.
Utilisez les cochettes de retour
`chaque fois que vous mentionnez une fonction, un objet ou un paquet dans votre prose.Utilisez les trois dernières cases à cocher
```pour séparer les morceaux de code de la prose.Faites attention à la fluidité et aux distractions.
4.1.3 Grammaire et style
Faites attention à la ponctuation, à l’orthographe et à la grammaire.
Faites votre mieux pour être clair et concis. Évitez les phrases trop longues.
Relisez l’atelier dans son intégralité pour vous assurer que le flux est bon.
N’hésitez pas à demander à votre pair en développement de réviser votre texte.
4.1.4 Apprentissage active
Les ateliers doivent être interactifs et comprendre des exercices et des sondages. Nous présentons ci-dessous quelques exemples d’exercices, de modes d’apprentissage fondés sur des données probantes et de stratégies efficaces pour organiser des ateliers à distance.
Nous vous recommandons de prendre votre temps et de bien planifier l’élaboration des exercices. Veillez à ce que les objectifs de l’exercice soient en adéquation avec ceux de l’atelier.
Rappelez-vous que tout ce qui est écrit dessous le
???est une note pour la personne qui présente et n’apparaîtra donc pas dans la diapositive de présentation, mais apparaîtra dans la fenêtre du mode présentation.
4.1.4.1 Sondages simples
Voir ci-dessous quelques exemples de deux diapositives contenant un exercice suivi de leurs solutions.
Exemple 1
Contexte : Les personnes participant à l’atelier viennent d’apprendre quelles fonctions utiliser pour effectuer des comparaisons entre groupes dépendants et indépendants, et ont également été initiés à la vérification d’hypothèses unilatérales et bilatérales.
Objectif : évaluer les connaissances des personnes participant à l’atelier et les rendre plus confiantes dans le choix du test à deux échantillons approprié dans leur recherche.
Elaboré par : Pedro Henrique P. Braga
---
Nous souhaitons évaluer si nous trouvons plus d'acromanthules dans les zones boisées et ombragées par rapport aux zones ouvertes. Nous sommes allés sur le terrain et avons compté le nombre d'individus (variable : `abundance`) dans dix paysages forestiers et ouverts répartis de manière aléatoire (variable : `type_of_area`). Laquelle des fonctions suivantes serait appropriée pour tester notre hypothèse ?
1. `t.test(type_of_area, abundance, data = acromantula_experiment, alternative = "two.sided")`;
2. `t.test(type_of_area, abundance, data = acromantula_experiment, paired = TRUE, alternative = "two.sided").`
3. `t.test(type_of_area, abundance, data = acromantula_experiment, alternative = "one.sided")`;
???
Note : Pendant ce moment, un sondage doit être ouvert. Une fois que vous avez obtenu les réponses de votre public, montrez-leur la bonne réponse. Vous pouvez demander à quelqu'un d'expliquer sa réponse.
---
Nous souhaitons évaluer si nous trouvons plus d'acromanthules dans les zones boisées et ombragées par rapport aux zones ouvertes. Nous sommes allés sur le terrain et avons compté le nombre d'individus (variable : `abundance`) dans dix paysages forestiers et ouverts répartis de manière aléatoire (variable : `type_of_area`). Laquelle des fonctions suivantes serait appropriée pour tester notre hypothèse ?
1. `t.test(type_of_area, abundance, data = acromantula_experiment, alternative = "two.sided")`;
2. `t.test(type_of_area, abundance, data = acromantula_experiment, paired = TRUE, alternative = "two.sided").`
3. `t.test(type_of_area, abundance, data = acromantula_experiment, alternative = "one.sided")`; #<<
???
Note : Vous devez préciser la distinction entre les tests d'hypothèse bilatéraux et unilatéraux (i.e. one-sided and two-sided; dans le contexte du problème). En outre, vous devez également rappeler les différences entre les mesures dépendantes et indépendantes (en rapport avec l'argument `paired`).
---Exemple 2
Contexte : Les personnes participant à l’atelier ont été initiés aux modèles linéaires généralisés, et viennent d’apprendre la distribution de Poisson, ses hypothèses selon lesquelles la variance est égale à la moyenne, et comment la sur-dispersion de leurs données peut être un problème lors de l’ajustement de ces modèles. Ils ont été initiés à la famille quasi-Poisson et à la possibilité d’appliquer une correction de sur-dispersion pour les données binaires avec l’objet de famille “quasibinomial”.
Objectif : Évaluer la capacité à appliquer le concept de correction de la sur-dispersion à différents types de données, pour aider à mieux comprendre la relation entre les objets de famille et les fonctions de liaison, et pour renforcer l’idée que les modèles peuvent être mis à jour sans avoir à en créer de nouveaux.
Elaboré par : Esteban Góngora
---
Nous avons maintenant réalisé que l'exemple de proportion pour les cerfs infectés peut avoir des problèmes de surdispersion (la variance augmente beaucoup plus vite que la moyenne). Laquelle des fonctions suivantes serait une mise à jour appropriée pour tenir compte de la surdispersion dans nos données sur les proportions ?
1. `prop.reg.quasi <- glm(prop.infected ~ res.avail, family = quasipoisson(link = "logit"), weights = n.total)` ;
2. `prop.reg.quasi <- glm(prop.infected ~ res.avail, famille = quasibinomial, poids = n.total)` ;
3.`prop.reg.quasi <- update(prop.reg2, family=quasibinomial(link = "logit"))` ;
???
Note : Pendant ce moment, un sondage devrait être ouvert. Une fois que vous avez obtenu les réponse de votre public, montrez-leur la bonne réponse. Vous pouvez demander à quelqu'un d'expliquer sa réponse.
---
Nous avons maintenant réalisé que l'exemple de proportion pour les cerfs infectés peut avoir des problèmes de surdispersion (la variance augmente beaucoup plus vite que la moyenne). Laquelle des fonctions suivantes serait une mise à jour appropriée pour tenir compte de la surdispersion dans nos données sur les proportions ?
1. `prop.reg.quasi <- glm(prop.infected ~ res.avail, family = quasipoisson(link = "logit"), weights = n.total)` ;
2. `prop.reg.quasi <- glm(prop.infected ~ res.avail, famille = quasibinomial, poids = n.total)` ;
3. `prop.reg.quasi <- update(prop.reg2, family=quasibinomial(link = "logit")) #<<` ;
???
Note : Vous pouvez maintenant expliquer que nous pouvons obtenir le modèle corrigé avec les options 2 et 3. Cependant, l'option 3 est le bon choix car vous aviez demandé de mettre à jour le modèle `prop.reg2`. Vous pouvez également rappeler que chaque distribution a une fonction de lien par défaut, donc l'utilisation de `family = quasibinomial` et `family=quasibinomial(link = "logit")` produira le même résultat que `logit` est la fonction de lien par défaut pour la distribution quasibinomiale.
---4.1.4.2 Exercice de groupe
Le travail en petits groupes permet d’exploiter les forces de chaque membre du groupe et d’améliorer le succès du cadre collectif. Cet exercice exige un répartition au hasard de l’audience dans des salles de discussion (idéalement, 5 personnes par salle) et doit comprendre une activité se rapportant à un point de discussion. À la fin de cet exercice, les groupes sont reconvoqués et une personne de chaque salle de discussion doit faire un rapport et résumer la discussion. Cette activité doit durer environ 10 minutes (parfois moins si elle est très simple) et doit utiliser les informations qui ont été fournies pendant l’atelier.
Voir ci-dessous deux exemples de diapositives contenant un exercice suivi de sa solution :
Exemple 1
Contexte : Cet exercice doit être fourni pour préparer le terrain aux discussions lors d’un atelier de visualisation de données. Il n’exige pas une connaissance solide de la visualisation de données.
Objectif : Encourager la réflexion critique autour de la visualisation de données.
Élaboré par : Pedro Henrique P. Braga
---
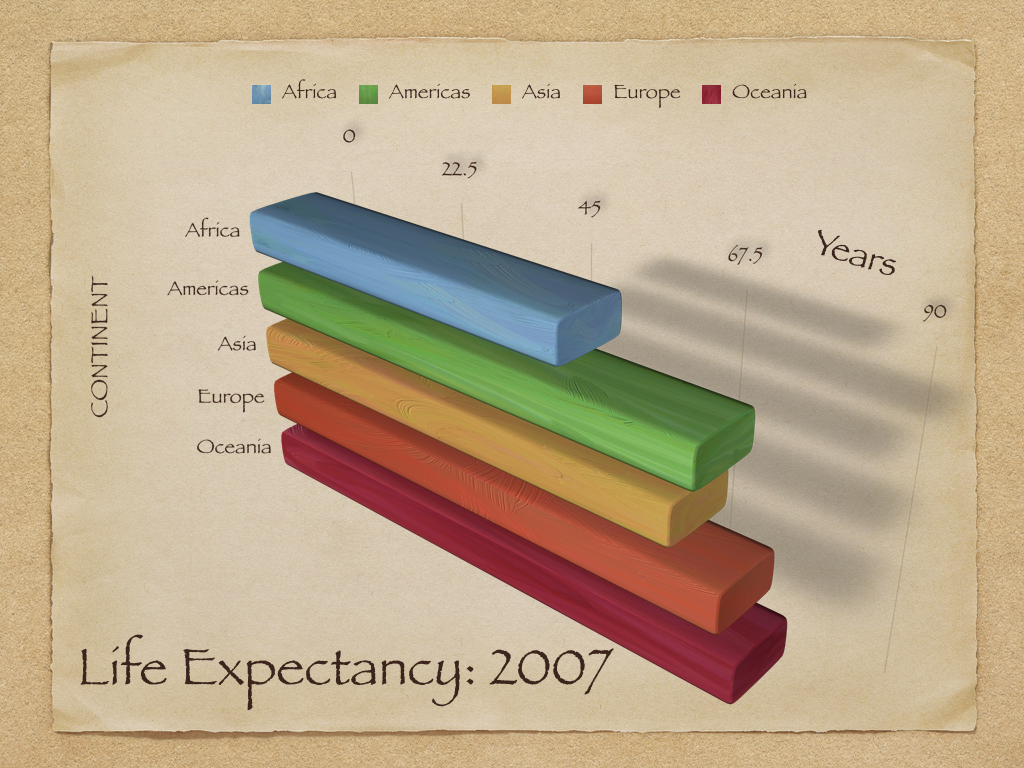
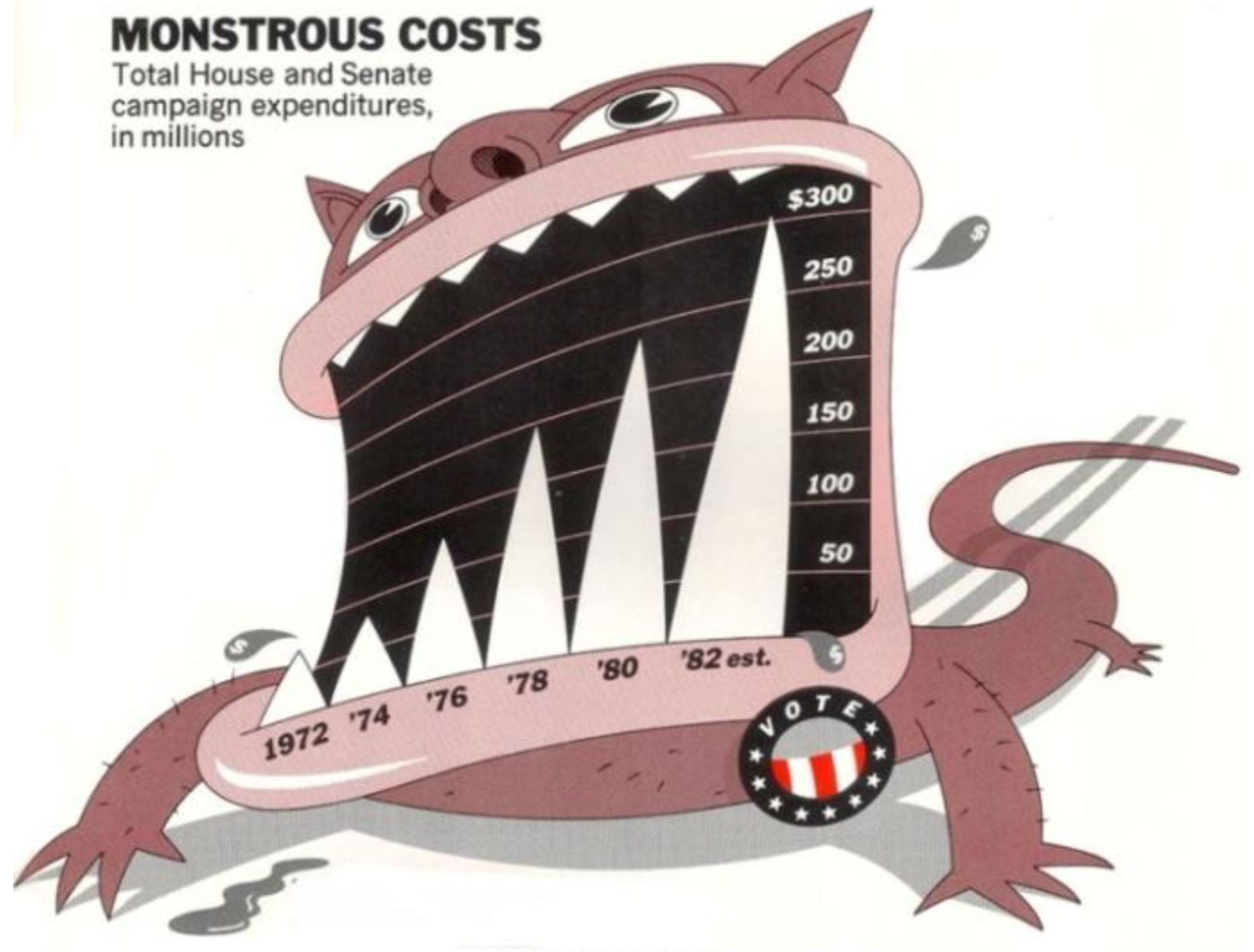
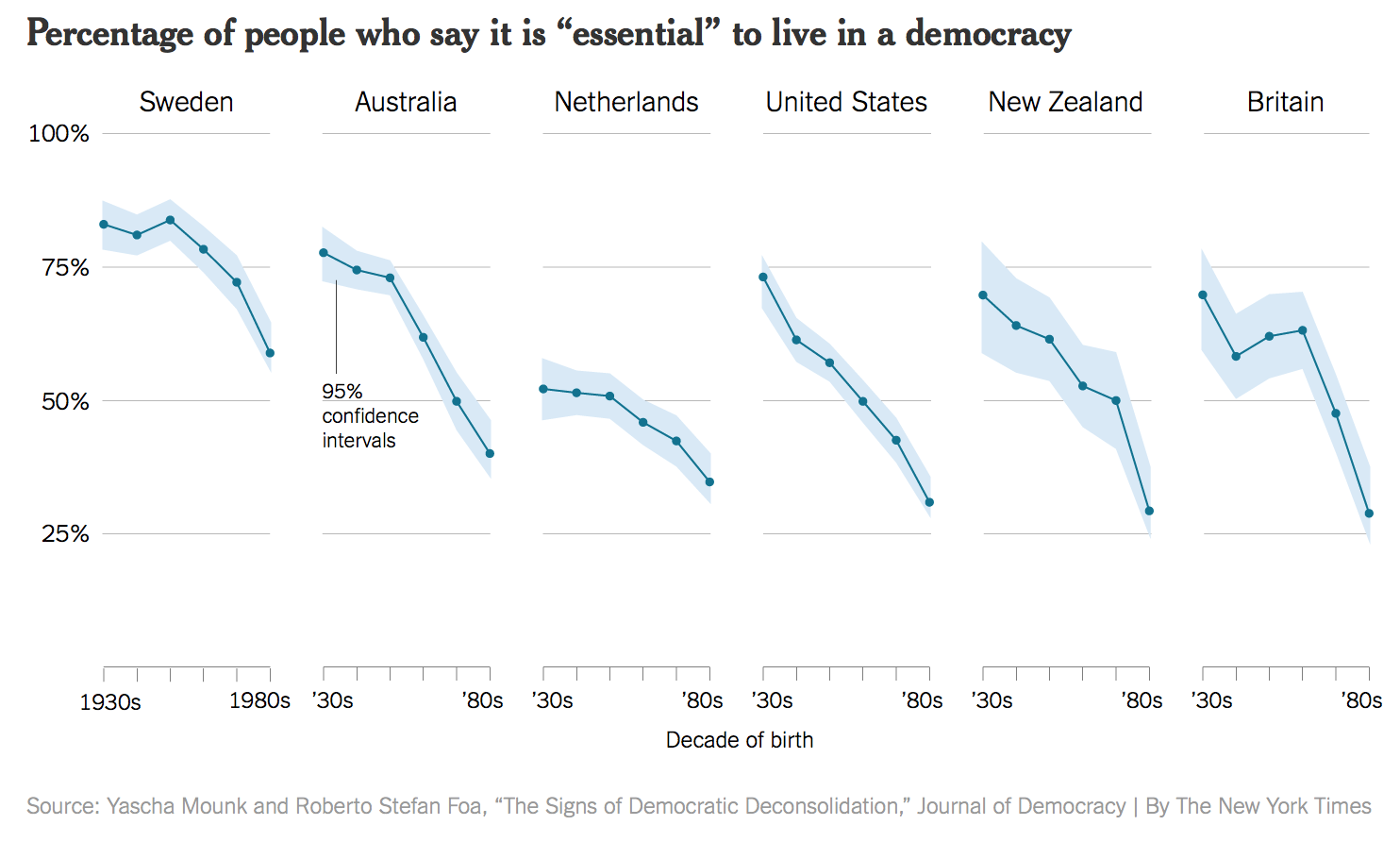
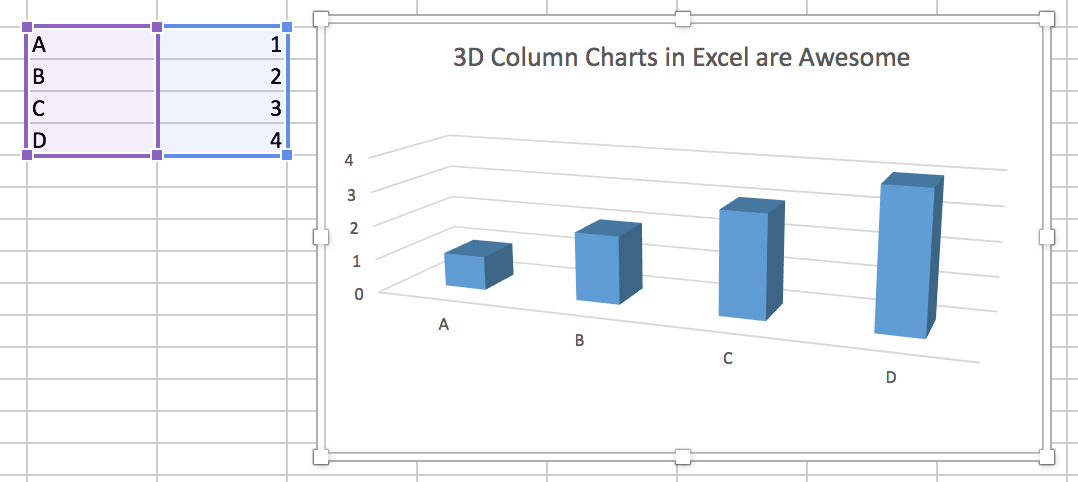
Discussion de groupe : Vous trouverez ci-dessous trois graphiques compilés à partir d'un livre de visualisation (référence indiquée dans la diapositive suivante). Ouvrez et observez les tableaux et discutez avec votre groupe pour répondre aux questions suivantes :
(a) Quels problèmes voyez-vous dans chacun des tableaux ?
(b) Quelles sont les conséquences de ces problèmes que vous avez identifiés ?
(c) Que changeriez-vous dans chacun d'eux pour améliorer leur information ?
### Ajoutez ces images côte à côte.
???
Note : Lisez clairement l'exercice. Demandez un résumé des réponses et qu'une personne doit ensuite faire un compte rendu de la discussion lorsque la classe est convoquée. Vous pouvez prévoir 5 à 8 minutes pour la discussion dans les salles de discussion (en fonction de la taille du groupe) car il s'agit d'un exemple très simple.
---
Discussion de groupe : Vous trouverez ci-dessous trois graphiques compilés à partir d'un (livre de visualisation) [https://socviz.co/lookatdata.html]. Ouvrez et observez les tableaux et discutez avec votre groupe pour répondre aux questions suivantes :
(a) Quels problèmes voyez-vous dans chacun des tableaux ?
(b) Quelles sont les conséquences de ces problèmes que vous avez identifiés ?
(b) Que changeriez-vous dans chacun d'eux pour améliorer leur information ?
### Afficher les images côte à côte

???
Note : Les chiffres en question ne sont pas seulement une question de mauvais goût (subjectif), mais ont des problèmes liés à la manière dont ils transmettent l'information. Dans cet exemple, le problème n'est pas dû à une différence dans la façon dont l'axe des y est dessiné. Il s'agit plutôt d'une mesure différente : nous examinons maintenant la tendance du score moyen, plutôt que la tendance de la réponse la plus élevée possible.
---Exemple 2
Contexte : Les personnes qui participent viennent d’être initiés aux analyses multivariées, et viennent de voir le tableau récapitulatif des principales caractéristiques des ordinations sans contrainte.
Objectif : Permettre auxpersonnes qui participent d’appliquer de manière critique les informations présentées dans cet atelier en déterminant quel type d’étude/données correspondrait le mieux aux différents types d’ordinations.
Elaboré par : Esteban Gongora Bernoske
---
Discussion de groupe : Chaque groupe se verra attribuer au hasard un type d'ordination. Vous discuterez au sein de votre groupe des types d'ensembles de données possibles qui correspondent le mieux au type d'ordination qui vous a été attribué. Chaque groupe présentera un exemple concret de projet/étude/expérience qui serait utilisé avec sa méthode d'ordination.
### Inclure le tableau récapitulatif pour référence.
)
???
Note : Lisez clairement l'exercice et attribuez à chaque salle de discussion un type d'ordination. Suggérez l'utlisation des caractéristiques du tableau récapitulatif pour trouver la réponse, puis une personne doit faire un compte rendu de la discussion lorsque la classe est convoquée en présentant l'exemple choisi et en mentionnant brièvement la raison pour laquelle elle l'a choisi. Vous pouvez prévoir 5 à 8 minutes pour la discussion dans les salles de discussion (en fonction de la taille du groupe). Pendant les discussions en sous-groupes, pensez à des exemples possibles que vous pourriez leur donner au cas où la discussion ne se déroulerait pas comme prévu (n'oubliez pas que c'est la fin de l'atelier et que votre public peut donc être déjà fatigué).
---
Discussion de groupe : Chaque groupe se verra attribuer au hasard un type d'ordination. Vous discuterez au sein de votre groupe des types d'ensembles de données possibles qui correspondent le mieux au type d'ordination qui vous a été attribué. Chaque groupe présentera un exemple concret de projet/étude/expérience qui serait utilisé avec sa méthode d'ordination.
### Inclure le tableau récapitulatif pour référence.
)
???
Note : Mentionnez quelques exemples ou utilisez les exercices présentés pendant l'atelier pour conclure la discussion.
---4.1.4.3 Exercice individuel
Des exercices individuels simples demandent à chacun de pratiquer un peu par soi-même. En fonction de la difficulté des exercices, pensez à prévoir entre 5 et 10 minutes pour leur exécution.
Bien que ces exercices aident à assimiler le contenu, certaines personnes peuvent être moins motivées pour les exécuter (contrairement aux exercices de groupe). C’est pourquoi il faut envisager d’inclure d’autres types d’exercices en plus de ceux-ci.
À la fin de ces exercices, donnez l’occasion à une ou quelques personnes de présenter et de discuter leurs réponses.
Ci-dessous, nous pouvons voir un exemple d’exercice indépendant et sa solution :
Contexte : L’atelier vient d’aborder les familles de distribution, les fonctions de liens et des exemples du fonctionnement des fonctions glm() et manyglm().
Objectif : Encourager l’observation les tracés de diagnostic lors du choix de modèle.
Élaboré par : Pedro Henrique P. Braga.
---
Utilisez `manyglm()` pour estimer les réponses de la composition de la communauté d'acariens à toutes les variables environnementales associées à l'ensemble de données sur les `acariens`. Quelles familles d'erreurs (gaussiennes, de poisson ou binomiales négatives) correspondent le mieux aux données ?
N'oubliez pas de charger les bibliothèques `vegan` et `mvabund`, et d'utiliser `data(mite)` et `data(mite.env)` pour charger les ensembles de données.
Conseil : Souvenez-vous de ce que nous avons dit sur les hypothèses de modèle !
???
Note : L'objectif de cet exercice est de permettre d'écrire indépendamment les modèles, d'assigner les arguments appropriés liés aux familles de distribution et de réaliser qu'ils doivent tracer les résidus par rapport aux valeurs ajustées pour décider du meilleur modèle. Rappelez ce que les deux ensembles de données comprennent. Vous pouvez aider votre public à se rendre compte des arguments possibles en suggérant la fonction d'aide "?`". À la fin de cet exercice, invitez quelques personnes à partager leur réponse et demandez-leur comment ils l'ont obtenue.
---
Utilisez `manyglm()` pour estimer les réponses de la composition de la communauté d'acariens à toutes les variables environnementales associées à l'ensemble de données sur les `acariens`. Quelles familles d'erreurs (gaussiennes, de poisson ou binomiales négatives) correspondent le mieux aux données ?
Solution :
### À afficher à l'intérieur d'un bloc de code:
mitedat <- mvabund(mite)
mite.gaussian.glm <- manyglm(mitedat ~ SubsDens + WatrCont + Substrat + Arbuste + Topo, data = mite.env, family='gaussian')
mite.poisson.glm <- manyglm(mitedat ~ SubsDens + WatrCont + Substrat + Arbuste + Topo, data = mite.env, family='poisson')
mite.nb.glm <- manyglm(mitedat ~ SubsDens + WatrCont + Substrat + Arbuste + Topo, data = mite.env, family='negative.binomial')
# Afficher les tracés de diagnostic côte à côte :
par(mfrow=c(1,3))
plot(mite.gaussian.glm)
plot(mite.poisson.glm)
plot(mite.nb.glm)
### Fin de la partie du code
???
Note : Montrez clairement quels arguments ont changé entre les fonctions et ce qu'ils impliquent. Expliquez comment les hypothèses de distribution des résidus et des valeurs prédites doivent encore être satisfaites pour que les modèles soient considérés comme valables.
---4.3 Contribuer autrement
Si vous n’êtes pas à l’aise avec GitHub, vous pouvez toujours nous aider à améliorer les ateliers !
Si vous trouvez des erreurs ou des incohérences, ou si vous souhaitez faire une suggestion, que ce soit sur la forme ou le contenu, vous êtes invités à ouvrir un numéro. Vous pouvez suivre ces étapes simples pour créer un nouveau numéro.
4.2 Comment développer des ateliers
Cette section vous guide à travers le processus de contribution aux présentations des ateliers R du CSBQ.
4.2.1 Pour commencer
Les ateliers R du CSBQ sont des présentations créées en utilisant xaringan, donc la première étape est d’installer la bibliotèque
Rxaringan.Ensuite, vous devez créer une copie locale du répertoire de l’atelier sur lequel vous travaillerez, que vous trouverez ici. Pour ce faire, vous pouvez cloner le répertoire GitHub sur votre ordinateur.
Pour ce faire, vous pouvez utiliser la ligne de commande (plus de détails ici) :
Si vous n’êtes pas à l’aise avec la ligne de commande, vous pouvez cloner ce dépôt d’archives en utilisant GitHub Desktop, en suivant les instructions ici.
Une fois que vous avez cloné le dépôt d’archives, vous êtes prêt à commencer le développement !
4.2.2 Flux de travail GitHub
GitHub crée des dépôt d’archives avec une seule branche par défaut, nommée
dev(si vous travaillez en ligne de commande) oumain(si vous travaillez dans GitHub Desktop). C’est la branche que vous voyez quand vous visitez le dépôt d’archives.Nous vous recommandons fortement de travailler sur une nouvelle branche, qui vous permet de développer les ateliers sans affecter la branche principale du dépôt d’archives. Travailler sur une branche distincte signifie que les changements ne sont mis en œuvre dans le contenu original qu’une fois que vos contributions ont été examinées. C’est une façon “plus sécuritaire” de développer les ateliers, particulièrement lorsque plusieurs personnes collaborent sur un atelier en même temps.
workshop1_introsi vous travaillez sur l’introduction de l’atelier 1.Sur la ligne de commande :
Github Desktop (instructions ici).
Sur la ligne de commande :
GitHub Desktop (instructions ici).
Effectuez vos modifications, en suivant les lignes directrices énumérées ci-dessus.
Ajoutez et validez vos modifications. Une fois que vous avez terminé de faire des changements sur votre branche, ajoutez-les et validez-les pour enregistrer ces changements. Lorsque vous validez des modifications, il est essentiel d’inclure un message de validation qui résume brièvement ce que vous avez fait. Soyez bref mais informatif !
Sur la ligne de commande :
Vous pouvez également utiliser GitHub Desktop pour ajouter des modifications (instructions ici) et les valider (instructions ici).
Tirez le
devsur la ligne de commande :Tirez la branche
mainsur GitHub Desktop (instructions ici).workshop1_intro) et fusionnez-la avec votre branche principale locale. S’il y a des conflits, veuillez les résoudre !Vous pouvez fusionner votre branche avec la branche
deven utilisant la ligne de commande :Fusionnez votre branche avec la branche
maindans GitHub Desktop (instructions ici).En ligne de commande, vous pouvez pousser votre branche fusionnée localement (par exemple
workshop1_intro) vers le dépôt d’archives distant comme ceci :Poussez votre branche (par exemple
workshop1_intro) vers le dépôt d’archives distant dans GitHub Desktop (voir étape #4).Les pull requests ou demandes d’extraction sont un moyen de faire connaître à votre équipe de développement les changements que vous avez poussés vers une branche du dépôt Github. Une fois que vous avez ouvert une demande d’extraction, nous pouvons examiner les changements potentiels et ajouter des commandes de suivi (si nécessaire) avant que vos changements ne soient fusionnés dans la branche principale.
Pour ouvrir une demande d’extraction pour votre branche (par exemple
workshop1_intro), veuillez suivre ces instructions.Assignez votre demande d’extraction à l’équipe de coordination des ateliers R du CSBQ. Votre demande sera révisée et fusionnée avec le dépôt principal.
Une fois que la demande d’extraction est fusionnée, n’oubliez pas de tirer la branche principale !
Un guide visuel du flux de travail GitHub est aussi accessible ici.